大模型的检索增强-NanoGraphRAG
一. RAG和GraphRAG
1.1 什么是RAG
RAG(Retrieval Augmented Generation,检索增强生成)是一种将信息检索技术与生成式语言模型(LLM)结合的AI框架。它通过从外部知识库中检索相关信息,然后使用这些信息增强LLM的提示词(prompt),从而生成更准确、更相关、更全面的答案。
大模型为什么需要RAG:
- 如果一个llm在pretrain之后没有做rag(外部检索)的话,其实往往可能存在幻觉。
- 基座模型在专业领域知识不足,比如一些医药、法律等。
- 外挂知识需要长期实时维护更新的。
1.2 RAG在LLM中LangChain的例子
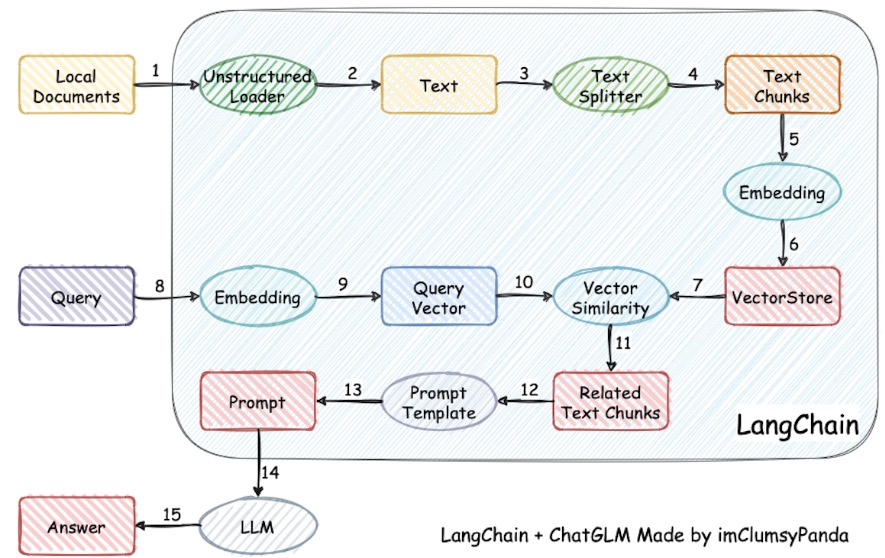 如上图所示,整个RAG的过程分为三个部分:
如上图所示,整个RAG的过程分为三个部分:
- 文本嵌入阶段:将本地文本进行分段后,利用embedding模型对其每个段落进行词嵌入,并将其vector存入向量数据库(比如FAISS、Chroma)中。
- 请求阶段:对大模型进行请求之前,会将请求的文本同样利用embedding模型转成向量,然后会和向量数据库中比对相似度最高的本地文本段落,并将其作为关联的文本段放到prompt中。
- 输出阶段:将提示词 + 本地文本关联段落 + 请求一起输入大模型,得到输出。
1.3 GraphRAG的定义及其优势
GraphRAG是一种基于知识图谱的检索增强技术,通过构建图模型的知识表达,将实体和关系之间的联系用图的形式进行展示,然后利用大语言模型LLM进行检索增强。 论文:From Local to Global: A Graph RAG Approach to Query-Focused Summarization
GraphRAG比RAG优势在哪:
- RAG过于局限:RAG仅能检索到与query相速度最高的文本片段,无法从全局出发来看整个本地文本。
- GraphRAG通过构建实体关系图谱实现了信息间的连接,能从全局出发,能更完整地理解和检索复杂的关联信息,从而生成更准确和全局性的结果。
1.4 GraphRAG的流程
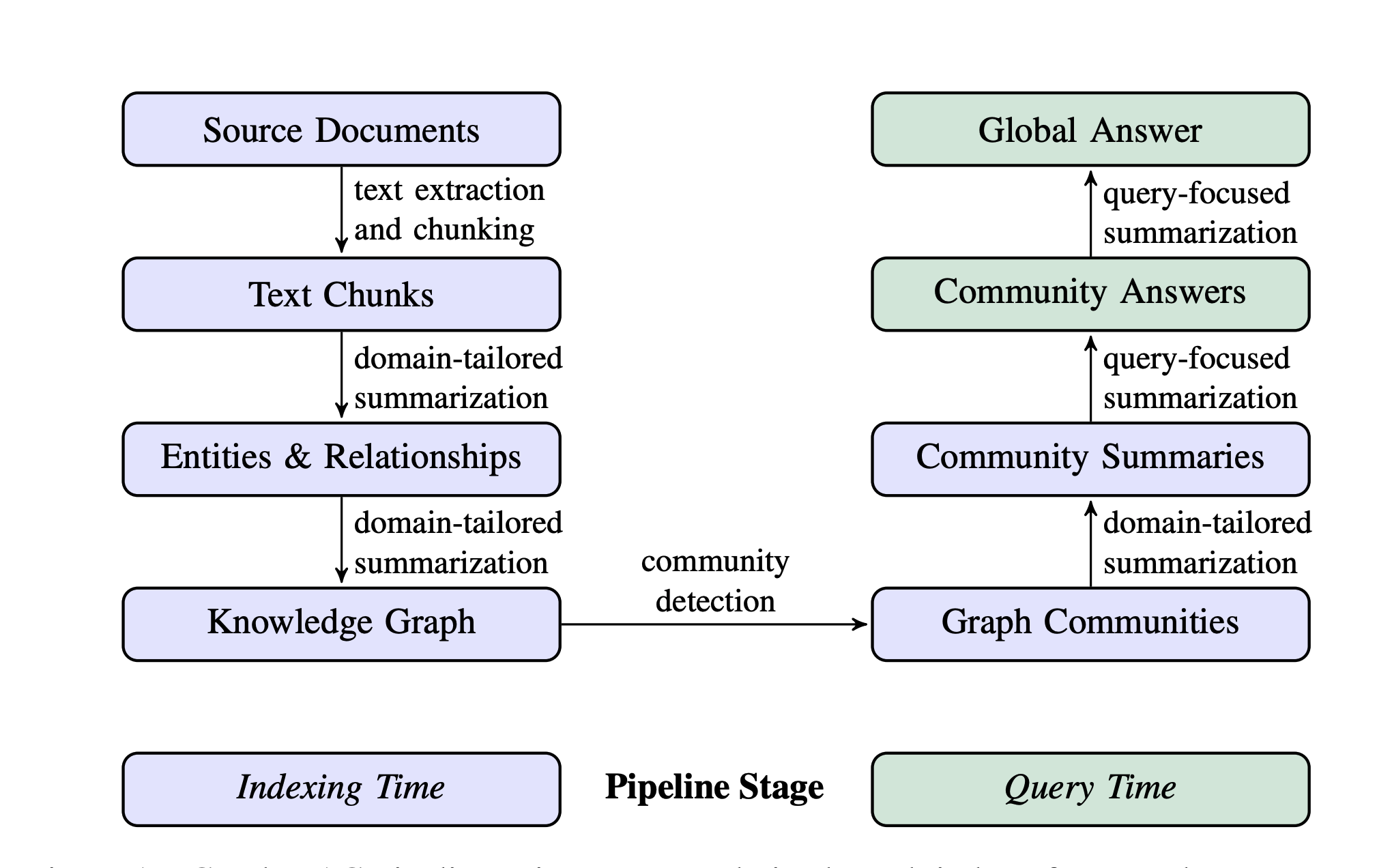 如上图所示,就是GraphRAG的处理流程图,其实总结起来就两个部分:
第一部分:构建知识图谱
如上图所示,就是GraphRAG的处理流程图,其实总结起来就两个部分:
第一部分:构建知识图谱
- 将本地文本进行分段
- 对每个段落进行摘要提取:这里完全依赖于大模型的提取能力
- 实体和关系的提取:这里完全依赖于大模型的提取能力,实体和关系抽取可以参考本人之前写的《事件抽取实战》这篇文章
- 构建知识图谱,写入数据库
第二部分:利用构建的知识图谱回答问题
- 社区检测:实际就是一种图聚类的方法,这里的“社区”,我们可以将其理解为一类具有相同特性的节点的集合。
- 社区总结:给每个社区创建类似报告的摘要。利于理解整体的结构和语义。
- 生成全局答案:给定用户查询,基于上一步生成的社区摘要可用于在多阶段过程中生成最终答案。
二. GraphRAG的轻量版本——nano-GraphRAG
对于GraphRAG而言,其封装的太死,代码量又很大,对于定制化的任务而言,不太好下手,因此推荐一个轻量化的版本——nano-GraphRAG。
代码:https://github.com/gusye1234/nano-graphrag
相较于GraphRAG的优势:
- 代码量少:包含了tests + prompt也才只有1100行代码!
- 更容易阅读
- 给的例子太好用了,直接上手没有难度。
2.1 安装
这里推荐不用官方推荐的pip install 来安装。因为这样会对于代码和prompt不好调整。
直接clone项目即可,然后安装其依赖pip install -r requirements.txt
2.2 基于ollama的nano-GraphRAG的三国例子
由于nano-Graphrag中的例子已经包含ollama形式的调用大模型的方式,因此开箱即用即可:
- 找到
examples/using_ollama_as_llm_and_embedding.py,这里需要你更改embedding大模型和chat大模型,我这里选择了魔塔社区的embedding模型,注意由于我们使用的是ollama来本地启动大模型,因此需要选择的是GGUF格式的模型。MODEL = "deepseek-r1:8b" EMBEDDING_MODEL = "modelscope.cn/yingda/gte-Qwen2-1.5B-instruct-GGUF:latest" EMBEDDING_MODEL_DIM = 1536 - 配置工程目录:
WORKING_DIR = "/LLM/nano-graphrag/three_kingdom_ds" - 修改insert的文件地址:
with open("/LLM/nano-graphrag/three_kingdom_ds/三国演义.txt", encoding="utf-8-sig") as f:
- 使用ollama开启本地模型
ollama run deepseek-r1:8b ollama run modelscope.cn/yingda/gte-Qwen2-1.5B-instruct-GGUF:latest
然后直接python examples/using_ollama_as_llm_and_embedding.py就会自动构建知识图谱 + 查询了。
2.3 爬坑
之前本人已经实验过qwen3:8b,亲测会报错leiden.EmptyNetworkError: EmptyNetworkError
然后解决方案有2种:
- 更换大模型,比如像上面使用
deepseek-r1:8b或者mistral:7b都可以的 - 更改prompt
然后推荐测试的话,可以不用上来就用《三国演义》,不然可能跑了好几个小时,发现出现问题,那真的搞心态啊!