从 LLM 到 Agent:原理、架构与协作模式全景
一. Agent的由来
1.1 什么是Agent
这里使用Claude Code作为例子来解释Agent到底是什么
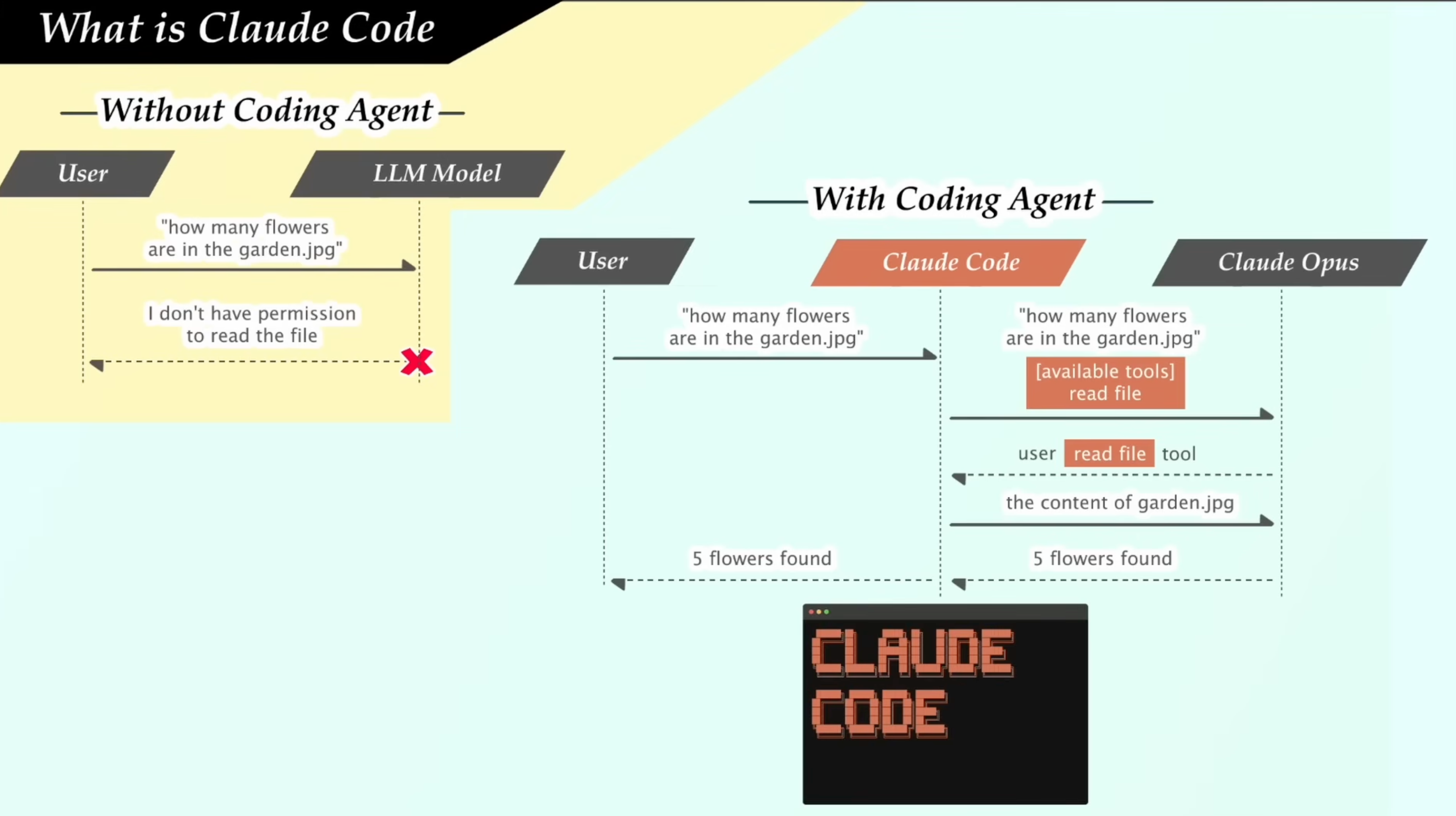
我们可以将Claude Code当作为一个Coding Agent:
- 没有Coding Agent:LLM模型没有相关的权限和工具来解决用户提出的问题
- 有Coding Agent:
- 用户提问:直接问 “garden.jpg 里有几朵花?”
- Claude Code 自动调用工具:
- 用
read file工具读取本地图片文件,获取文件内容 - 将图片内容传给 Claude Opus,进行视觉分析。如果这里是其他复杂任务,这里Coding Agent才会自动生成并运行脚本
- Claude Opus 分析后,直接返回 “找到了 5 朵花”
- 用
因此,Agent具备三要素:
- Prompts:
- 角色是什么
- 能做什么
- 不能做什么
- Context Management:
- 有限的context window
- 对话历史
- RAG匹配的数据
- Tools:
- 做事的:比如订酒店,输出文档等
- 查询的:查询数据库、天气
1.2 LLM为什么需要Agent—Harness
LangChain 团队 “用 LLM+Agent 打败纯 LLM”,最典型、最权威的公开案例是:在不换底层模型的前提下,通过给 LLM 套上 Agent 框架 + 系统化工程(Harness Engineering),把编码智能体成绩从 52.8% 提升到 66.5%,从榜单 30 名开外打进前 5 名。
纯LLM有以下天然的短板(52.8%):
- 知识截止:不会查资料,硬编命令,知识也截止到LLM训练的预料时间节点内。
- 幻觉:没见过的,可能硬生成虚无缥缈的东西。
- 偏离路径:过于发散,生成的结果可能会飘的很远。
- 没有分步规划:复杂任务(调试、多文件、环境配置)一步到位,容易崩。
- 无法使用工具:无法调用其他工具来执行指令。
Langchain团队的Harness Engineering(66.5%):
- 强化 System Prompt(给 Agent 一本 “工作手册”)
- 明确要求分步思考、先规划再行动、必须校验结果。
- 强制格式:每次输出必须包含
Thought、Action、Action Input,便于解析和执行。 - 禁止幻觉:不知道就去查,不许瞎编。
- 接入强工具集(让 LLM 有手脚)
- Bash 工具:执行命令、安装依赖、运行程序、看报错。
- 文件工具:读 / 写 / 编辑代码、配置文件。
- Python REPL:运行代码、算结果、调试片段。
- 搜索工具:查文档、查报错、查最新 API。
- 加中间件 / 钩子(Middleware/Hooks)—— 防崩、防死循环
- 超时控制:单步超时自动终止,避免卡死。
- 死循环检测:连续 3 步重复动作 → 强制换策略或终止。
- 结果校验:关键步骤(如编译、运行)自动检查返回码 / 输出,失败自动重试或回退。
- 错误回溯:保存失败前状态,支持 “回到上一步换方法”。
- 用 LangSmith 做迭代优化(数据驱动)
- 跑大量测试,追踪每一步 Thought/Action/Observation。
- 分析失败模式:是规划错、工具用错、校验漏了,还是 Prompt 不好。
- 针对性改 Prompt、工具、流程 → 再测 → 再分析,闭环优化。
二. Agent的多种模式
这里推荐的是一片git代码,对agent的多种模式讲述的非常清晰:https://github.com/FareedKhan-dev/all-agentic-architectures,下面是针对这段代码的解读
2.1 基础增强模式:让单 Agent 更聪明 🧠
让一个 Agent 从「直接出答案」进化到「能反思、能用工具、能规划」。
| 模式 | agent本质 |
|---|---|
| 01 Reflection(反思) | 生成 → 自我批判 → 修正,循环改稿 |
| 02 Tool Use(工具调用) | 让 LLM 调外部 API/函数突破知识截止 |
| 03 ReAct(推理+行动) | Thought → Action → Observation 交错循环 |
| 04 Planning(规划) | 先列好完整步骤,再按计划执行 |
典型流程:
Reflection: Generate → Critique → Refine
ReAct: Thought ⇄ Action ⇄ Observation → Final
Planning: Plan → Execute step by step → Aggregate
何时用:单一 Agent 任务,输出质量、信息时效或步骤复杂度需要提升。
2.2 多 Agent 协作:让 Agent 像团队一样工作 👥
把任务交给一组分工的专家,或并行多视角,或动态路由。
| 模式 | agent本质 |
|---|---|
| 05 Multi-Agent | 固定流水线分工(PM → 架构师 → Coder → Reviewer) |
| 07 Blackboard | 所有 Agent 共享黑板,控制器机会式调度 |
| 11 Meta-Controller | 主管 Agent 把任务路由给最合适的专家 |
| 13 Ensemble | 多 Agent 并行独立分析 + Aggregator 综合 |
对比要点:
- Multi-Agent:流程固定 → 软件开发流水线
- Meta-Controller:智能路由 → 多功能 AI 平台一个入口
- Blackboard:开放协作 → 复杂诊断、动态情境
- Ensemble:投票式 → 高风险决策、降低偏见
何时用:单一 Agent 撑不起任务,需要专业分工或多视角综合。
2.3 高级记忆与推理:让 Agent 想得更深、记得更久 🧬
赋予 Agent 长期记忆与复杂关系推理能力。
| 模式 | Agent本质 |
|---|---|
| 08 Episodic + Semantic Memory | 向量库记对话 + 图库记事实,双记忆系统 |
| 09 Tree of Thoughts | 推理建模为树搜索,多分支评估剪枝 |
| 12 Graph(世界模型) | 知识存为「实体 + 关系」图,多跳遍历推理 |
记忆 vs 推理:
- 08 + 12 偏「记得更多」(FAISS 向量 / Neo4j 图谱)
- 09 偏「想得更深」(指数级思维分支搜索)
何时用:
- 长期个性化助手 → 08
- 关系密集型问答(投资关系、文献引用)→ 12
- 强约束逻辑/数学难题(狼羊菜过河类)→ 09
2.4 安全与可靠:让 Agent 真敢上生产 🛡️
为 Agent 装上「三思而后行」与「自知之明」的护栏。
| 模式 | Agent本质 |
|---|---|
| 06 PEV(Plan-Execute-Verify) | 每步执行后由 Verifier 检查,错了就重规划 |
| 10 Mental Loop(心智仿真) | 在沙盒中先模拟,再决定真实动作 |
| 14 Dry-Run Harness | 干跑 + 人审批,再真实执行 |
| 17 Reflexive Metacognitive | 维护「自我模型」,能说”我不知道,建议找人” |
安全光谱:
PEV → 自动错误恢复
Mental Loop → Agent 自己模拟自己审
Dry-Run → 人类把关,最强护栏
Metacognitive→ 越界即拒绝/转交人类
何时用:金融、医疗、法律、生产环境的不可逆操作;任何「错答即灾难」的领域。
2.5 学习与适应:让 Agent 越用越好 📈
通过反馈与涌现机制,让系统自我演进。
| 模式 | Agent本质 |
|---|---|
| 15 RLHF(自我改进) | Editor 批评 Author,沉淀高质量样本到金标库 |
| 16 Cellular Automata | 网格上多个简单 Agent 用局部规则涌现复杂行为 |
两种适应方式:
- 15 集中式:靠反馈闭环逐步优化(适合内容生产、代码生成)
- 16 分布式:靠涌现解决空间/规模问题(适合路径规划、群体仿真)
何时用:长期运行、需持续优化的系统;或大规模、高鲁棒性的分布式问题。
2.6 选型速查
| 你的需求 | 推荐 |
|---|---|
| 输出质量不够 | 01 Reflection / 15 RLHF |
| 要查实时信息 | 02 Tool Use / 03 ReAct |
| 任务步骤多且复杂 | 04 Planning / 06 PEV |
| 需要专家团队 | 05 Multi-Agent / 11 Meta-Controller |
| 多视角降低偏见 | 13 Ensemble |
| 灵活开放式协作 | 07 Blackboard |
| 长期个性化 | 08 Episodic+Semantic |
| 关系/逻辑深推理 | 12 Graph / 09 ToT |
| 不可逆动作要安全 | 14 Dry-Run / 10 Mental Loop / 06 PEV |
| 高风险领域咨询 | 17 Metacognitive |
| 大规模空间问题 | 16 Cellular Automata |
三. Multi Agent
3.1 单agent和multi agent的差异
一般而言,我们是鼓励使用单agent来解题,下面是单agent和multi agent的在定差异:
- 单agent:单个智能体独立思考、规划、调用工具、闭环完成全流程任务
- multi agent:多个分工智能体协同,各司其职、消息交互、分工协作完成复杂任务
核心差异如下:
| 对比项 | 单 Agent | 多 Agent |
|---|---|---|
| 分工模式 | 一人全包,无角色拆分 | 按职责拆分角色,各司其职 |
| 决策逻辑 | 统一大脑决策,串行执行 | 多角色协商、表决、分工决策 |
| 资源调用 | 独占工具与上下文 | 工具分片使用,信息互通共享 |
| 上下文复杂度 | 低,任务链路简单 | 高,多角色会话交互 |
| 开发成本 | 低,逻辑简洁易维护 | 高,需设计角色、通信、权限 |
| 容错能力 | 单点故障任务中断 | 可替补分工,容错性更强 |
3.2 Multi agent的2个场景例子
case1-平行处理: 旅游场景,需要参考和建议下航班,酒店和天气等情况
在这个场景中:
- 单agent:找航班 -> 找酒店 -> 看天气,需要agent一个一个做。
- Muti agent:设定三个agent,分别是订航班agent、订酒店agent、查天气agent,三个agent并行处理。
case2-层级处理: 智慧家居场景,其中包含中央节点通过层级的方式来管理、控制其他的agent
- Orchestrator(中央大脑):是层级(Hierarchical)主节点,负责接收用户指令、统筹任务、协调灯光 / 保全 / 温控 / 能源等设备 Agent。
- A2A(agent-to-agent,点对点):是设备 Agent 之间的直接通信链路,不经过中央 Orchestrator,直接交互。